깜박하고 프로시저를 백업안하고 변경했는데, 다행이 오라클 flashback기능이 테이블말고 프로시저에도 적용이 되어 있었다!!
이기능을 사용해서 프로시저를 복구해서 백업을 진행함
Category Archives: oracle query
pivot을 사용해서 날짜별로 값을 보여주기
시작일자, 종료일자를 가지고 있는 원본데이터와 캘린더 데이터를 조인해서 일별로 사용자의 실적을 만들어 준 후에 pivot을 사용해서 한줄로 사용자의 실적을 보여준다.
SELECT *
FROM (
SELECT AA.NAME, SUBSTR(BB.DT_DD,-2) AS DT_DD
FROM
(
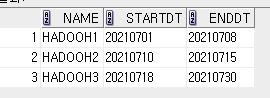
select 'HADOOH1' as name , '20210701' as startdt, '20210708' as enddt from dual union all
select 'HADOOH2' as name , '20210710' as startdt, '20210715' as enddt from dual union all
select 'HADOOH3' as name , '20210718' as startdt, '20210730' as enddt from dual
) AA,
(
SELECT * -- 해당월 캘린더정보
FROM CALENDAR
WHERE DT_DD LIKE '202107%'
) BB
WHERE 1=1
AND BB.DT_DD BETWEEN AA.STARTDT AND AA.ENDDT
)
PIVOT (
COUNT(*)
FOR DT_DD
IN ('01' as D01,'02' as D02,'03' as D03,'04' as D04,'05' as D05,'06' as D06,'07' as D07,'08' as D08,'09' as D09,'10' as D10
,'11' as D11,'12' as D12,'13' as D13,'14' as D14,'15' as D15,'16' as D16,'17' as D17,'18' as D18,'19' as D19,'20' as D20
,'21' as D21,'22' as D22,'23' as D23,'24' as D24,'25' as D25,'26' as D26,'27' as D27,'28' as D28,'29' as D29,'30' as D30
,'31' as D31)
)

오라클 정규식 REPLACE 특수문자 제거
SELECT TRIM(REGEXP_REPLACE(‘(010)-1!@1 1&%1-22**2 2’, ‘[^[:alnum:]+]’, ”))
FROM DUAL;
V$SQL 이란?
select sql_id, child_number, sql_text, sql_fulltext, parsing_schema_name -----① , sharable_mem, persistent_mem ,runtime_mem -----② , loads, invalidations, parse_calls, executions, fetches, rows_processed -----③ , cpu_time, elapsed_time-----④ , buffer_gets, disk_reads, sorts-----⑤ , application_wait_time, concurrency_wait_time-----⑥ , cluster_wait_time , user_io_wait_time-----⑥ , first_load_time, last_active_time -----⑦ from v$sql where to_char(last_active_time,'yyyymmdd') = '20160908'
오라클 V$SQL에 관련해서 잘 설명한 블로그가 있어서 링크해놓는다.
http://doraeul.tistory.com/80 – 도래울님 블로그
to_number(extractvalue~~!!)
select table_name, to_number(extractvalue(xmltype(dbms_xmlgen.getxml(‘select count(1) c from ‘||owner||’.’||table_name)),’/ROWSET/ROW/C’)) as count
from all_tables
where table_name like ‘%M40%’
;
테이블리스트를 가지고 테이블컬럼수를 가져오는 쿼리
COUNT(1) OVER()
SELECT
BB
,COUNT(1) AS COUNT_NORMAL
,COUNT(1) OVER(PARTITION BY CC) AS COUNT_OVER
,COUNT(CASE WHEN BB = CC THEN 1 ELSE NULL END) AS COUNT_CASE
FROM TABLE
GROUP BY BB
오라클 컬럼추가삭제수정, 행제거, 치환, 데이터입력, 다중테이블 다중행입력, pivoting, 데이터수정
[출처] 오라클 컬럼추가삭제수정, 행제거, 치환, 데이터입력, 다중테이블 다중행입력, pivoting, 데이터수정|작성자 josua21
http://blog.naver.com/PostView.nhn?blogId=kg00jh&logNo=220608266261
COMMENT ON TABLE tableuser.tablename IS ‘this is tablecomment’;
COMMENT ON COLUMN tableuser.tablename.columnname IS ‘this is columncomment’;
alter table em04 add (email varchar2(10)) ;
alter table em04 modify(email varchar2(50)) ;
alter table em04 drop column email ;
alter table em04 set unused (comm) ; — comm 사용하지 못하도록 설정
alter table em04 drop unused column ; –사용되지 않는 컬럼을 삭제하라
테이블의 컬럼/코멘트/컬럼사이즈/PK 뽑아내기
WITH ALL_TAB_PRIMARY_KEY AS (
SELECT — 테이블의 PK컬럼
CONS.OWNER, COLS.TABLE_NAME, COLS.COLUMN_NAME, COLS.POSITION, CONS.STATUS, ‘P’ AS PRIMARY_KEY
FROM ALL_CONSTRAINTS CONS, ALL_CONS_COLUMNS COLS
WHERE CONS.CONSTRAINT_TYPE = ‘P’
AND CONS.CONSTRAINT_NAME = COLS.CONSTRAINT_NAME
–AND CONS.TABLE_NAME = ‘(YOUR_TALBE_NAME)’
)
SELECT A.OWNER,A.TABLE_NAME,B.COMMENTS AS TABLE_DESC
,A.COLUMN_NAME,C.COMMENTS AS COLUMN_DESC,D.PRIMARY_KEY
,A.COLUMN_ID,A.DATA_TYPE,A.DATA_LENGTH,A.DATA_SCALE,A.NULLABLE
FROM ALL_TAB_COLUMNS A
,ALL_TAB_COMMENTS B
,ALL_COL_COMMENTS C
,ALL_TAB_PRIMARY_KEY D
WHERE A.OWNER = ‘(OWNER_NAME)’
AND A.OWNER = B.OWNER AND A.TABLE_NAME = B.TABLE_NAME
AND A.OWNER = C.OWNER(+) AND A.TABLE_NAME = C.TABLE_NAME(+) AND A.COLUMN_NAME = C.COLUMN_NAME(+)
AND A.OWNER = D.OWNER(+) AND A.TABLE_NAME = D.TABLE_NAME(+) AND A.COLUMN_NAME = D.COLUMN_NAME(+)
AND A.TABLE_NAME IN ( ‘(YOUR_TALBE_NAME)’ )
LISTAGG AND DISTINCT
LISTAGG를 사용해서 JOHN,LEE,SMITH,LEE,PARK,LEE 형식으로 데이터를 만들수 있다.
중간에 LEE 값을 중복제거를 하려면 REGEXP_REPLACE(CONTENTS,'([^,]+)(,\1)+’, ‘\1’) 를 사용해서 중복제거를 뽑아내자.
SELECT
DEPTNO
,LISTAGG(EMPNO, ‘,’) WITHIN GROUP (ORDER BY ROWNUM) AS ORIGINAL_DATA
,REGEXP_REPLACE(
LISTAGG(EMPNO, ‘,’) WITHIN GROUP (ORDER BY ROWNUM)
,'([^,]+)(,\1)+’, ‘\1′) AS REMOVE_DUPLICATE_DATA
— REGEXP_REPLACE(CONTENTS,'([^,]+)(,\1)+’, ‘\1’) — REMOVE THE DUPLICATE
FROM EMP_DATA
GROUP BY DEPTNO
만약에 WM_CONCAT을 사용할 수 있다면 간단하게 아래와 같이 DISTINCT를 집어넣으면 된다.
SELECT
DEPTNO
,wm_concat(name) names
,wm_concat(DISTINCT name) REMOVE_DUPLICATE_names
FROM EMP_DATA
GROUP BY DEPTNO
RPAD와 TO_MULTI_BYTE
전문전송시 베트남어를 처리할 때 문제가 있음
,rpad(NVL(EMPLOYEE_NUMBER,’ ‘),10,’ ‘) AS EMPLOYEE
,SUBSTRB(RPAD(NVL(TO_MULTI_BYTE(EMPLOYEE_NAME),’ ‘),30 ,’ ‘) || RPAD(‘ ‘,30,’ ‘),1,30) AS EMPLOYEE_NAME
,SUBSTRB(RPAD(NVL(TO_MULTI_BYTE(EMPLOYEE_ENGLISH_NAME),’ ‘),150 ,’ ‘) || RPAD(‘ ‘,30,’ ‘),1,30) AS EMPLOYEE_ENGLISH_NAME
참고.
TO_MULTI_BYTE(), RPAD() 전각, 전문 채우기(http://dobioi.com/453)
PL/SQL 문자열 함수 정리 (http://deviant86.tistory.com/m/post/456)